Back in old days by using SSIS, when we tried to create a data warehouse, for each dimension table will need to be setup a component in the package.
Nowadays with next gen lake house (Delta Lake) concept and databricks, this dimension table generation process (both SCD Type 1 and Type 2) can be super easy and the solution can be replicated for a different data mart. One notebook plus one configuration file can make this happen, and you can use ADF as an orchestrator.
I am not going to put detail code here, as this will take your pyspark coding fun, just providing some tips if you are interested with the “next gen” ETL.

Step 1: Create a notebook to handle one dimension table
There are three key things in this step:
-
Parameterize all the key factors to ensure this notebook can be used for another dimension table. For example:
table_name,schema_name,dim_qeury,primary_keysetc. More importantly, you can addschema_name_prefixto make the deployment easier switch from int to prod. As long as it eanbles the flexibily for this notebook but also not over complicated to manage. These would be your first section in the notebook. Once we finished the design, we can usetable_name = dbutils.widgets.get("")https://docs.microsoft.com/en-us/azure/databricks/notebooks/widgets (more details here) to accept the parameters value passed from ADF or another notebook. - Make the coding dynamic enough with no hard coding. Below is the sample code to Type2 dimension merge by using python from https://docs.delta.io/latest/delta-update.html#language-python. You will notice that the condition is using static column names, which all need to be replaced by a dynamic way for different dimension tables.
Some hints here:
- Table can be always alias as
targetandupdate. so we have a fix table name - When we receive parameters, we define the primary key, then use
dropmethod to get all the other column names - The condition is just a string, using
split,contact,for loop,etc to design a function generate a string liketarget.columnA = update.columnA and (target.ColumnB <> update.ColunB OR target.columnC <> update.ColumnC ....)
- Table can be always alias as
- Cover most of the situations in one notebook. As below sample code is only for SCD Type 2, we can have a
SCD Typeas input paramter and useifstatement to merge Type 1 and Type 2 code together. You can add more situations check likeif delta table exists,if you want do refresh start to remove all the files
customersTable = ... # DeltaTable with schema (customerId, address, current, effectiveDate, endDate)
updatesDF = ... # DataFrame with schema (customerId, address, effectiveDate)
# Rows to INSERT new addresses of existing customers
newAddressesToInsert = updatesDF \
.alias("updates") \
.join(customersTable.toDF().alias("customers"), "customerid") \
.where("customers.current = true AND updates.address <> customers.address")
# Stage the update by unioning two sets of rows
# 1. Rows that will be inserted in the whenNotMatched clause
# 2. Rows that will either update the current addresses of existing customers or insert the new addresses of new customers
stagedUpdates = (
newAddressesToInsert
.selectExpr("NULL as mergeKey", "updates.*") # Rows for 1
.union(updatesDF.selectExpr("updates.customerId as mergeKey", "*")) # Rows for 2.
)
# Apply SCD Type 2 operation using merge
customersTable.alias("customers").merge(
stagedUpdates.alias("staged_updates"),
"customers.customerId = mergeKey") \
.whenMatchedUpdate(
condition = "customers.current = true AND customers.address <> staged_updates.address",
set = { # Set current to false and endDate to source's effective date.
"current": "false",
"endDate": "staged_updates.effectiveDate"
}
).whenNotMatchedInsert(
values = {
"customerid": "staged_updates.customerId",
"address": "staged_updates.address",
"current": "true",
"effectiveDate": "staged_updates.effectiveDate", # Set current to true along with the new address and its effective date.
"endDate": "null"
}
).execute()
Step 2: Generate a config file includes all the parameters
This file can be a CSV file to easily read from databricks, for each dimension table matching to a row with parameters which will be used for the notebook.
Tip 1: do remember some parameter can be created in ADF directly as a high level control, e.g. schema_name_prefix can be controlled in pipeline level to switch from int to prod, instead of updating config file.
TIP 2: when reading this CSV file, using .option('multiline', True) to ensure the dim_query reading correctly.
Step 3: Orchestrate the whole process
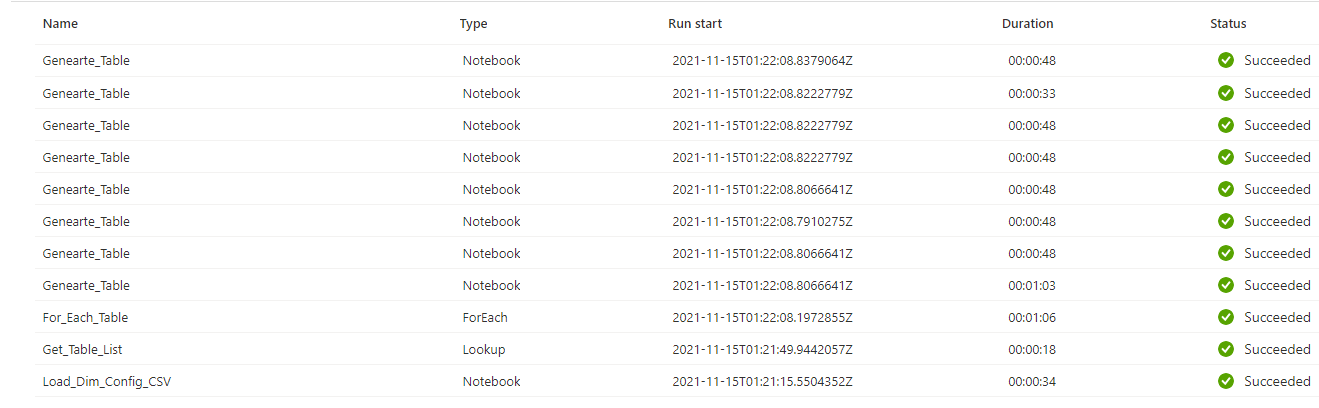
In this case, we are using ADF to do the job. I am not going to introduce details here, Copy multiple tables in Bulk with Lookup & ForEach this youtube video from Adam Marczak explains very clear. Basic step would be read the config file to create a config table, lookup the table and foreach passing the parameters to the notebook. Another youtube video here about Azure Data Bricks - Pass Parameter to NOTEBOOK from ADF Pipeline
One cool stuff is that ADF will make all these notebooks running in parallel.
Anything Else?
There is one issue as we all know is about databricks job cluster warming up, considering if we have multiple notebooks to run in this pipeline, e.g. to generate fact tables. The job culster will shutdown immediately after a notebook activity is done, so it will take very long time with ADF.
If we are not using ADF, can we use databricks notebook to orchestrate? can we still benefit from the “parallel” running when we for loop the config file? I am going to introduce this in my next blog.
Have Fun.
Eric Dong